Modeling data and information in an organization

The last weeks I’ve been focusing a lot on the data and information models in our architecture. Organizations have so much data flowing around that it’s hard to effectively map it all out. That’s a shame because there are some very valuable learnings to be had from that data.
That’s why I wrote this post; it’s mainly to gather my current thoughts on this topic. Might as well share it with you. It’s a combination of techniques I’ve done at previous organizations (things I know work) and things I’ve been thinking about for a long time now (things that might work). So this isn’t a full-on manual, more a collection of current thoughts. I hope that makes sense.
What is data, and what is information?
Like usual in these kinds of posts, we have to get some lingo straight. In the case of this post, it’s the difference between data and information. 1
I know there are different visions on this, but in the realm of enterprise architecture, data is the raw stuff. Think of a random JSON file that floats between two applications. It might be in the form of user.json or invoice.pdf.
Take, for example, a user.json that flows between application A and application B. At the same time, there is another user.json. going between application B and application X. These two files might have different data in them. For example, the one between applications A and B might only have personal data in it, then application B takes this file, adds organizational data to it, and sends it to application X.
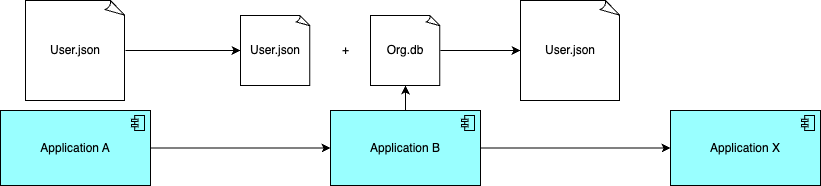
They are both user data, but they contain different points of data.
Now if we make an abstraction of that user.json, we get information. This would be the user information component. There is only one instance of a user information component. You link different types of data to this information component to bundle them into one concept. When you talk at a high level about what data flows between two applications, you talk about information; if you dig in to really determine a solution, you will switch over to data.
If you want to know more about this and why we would want to do this, please check out the previous post: Turning Complexity into Manageable Complication.
How I like to model it
As you know, I like to use ArchiMate with some TOGAF concepts in it, so that’s also how I model it.
We first start with a top-level flow connection between two applications.

One of the quirks of Archimate is that you can’t add a connection to a connection 2, so you need something called an interface. These interfaces seem very bothersome at first, but these components can also carry fields and can come in handy. So if you want to tag all connections that go over an enterprise service bus, an interface would be a good place to store that information.
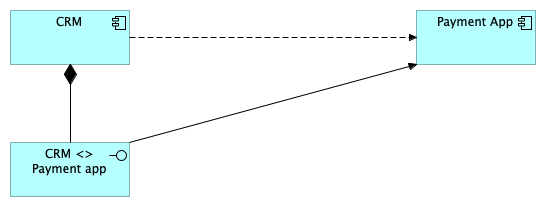
Now you might notice that we have a double set of connections going on. The original flow connections between the applications and the interface connection (compose and trigger 3). Some architectural tools allow you to collapse “composes” relations so you don’t see them. If you don’t use a tool like that I’m affraid you’re going to have to suffer the extra connections.
Once we have the interfaces in place, we can start adding the data to the applications.
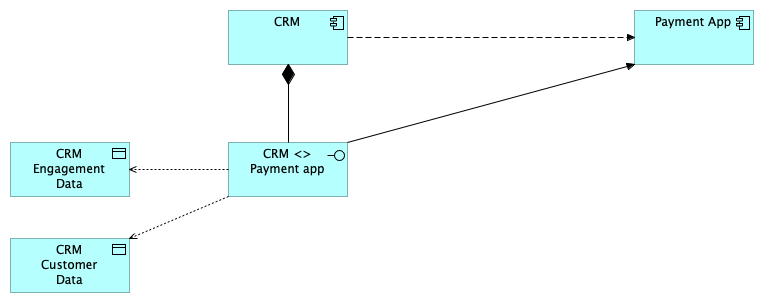
Here we can see, per interface, the data that flows between each application. It’s very rare in my experience that an application has more than one interface between a standard connection, but we will talk about that in the “details” section.
The last step is to link the data to the information. To do this, we simply connect the data component to the information component like this:
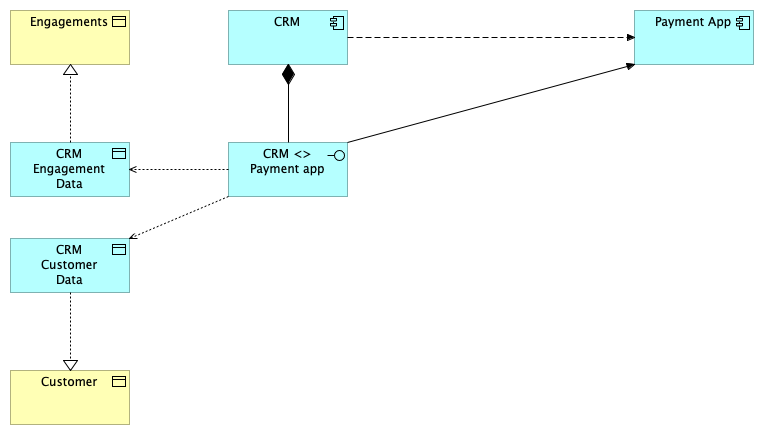
The benefits for the organization
So that’s the basic setup. You can see what data flows between applications; that’s nice. But you might not see the upside of that information layer yet. Well, let me tell you, that’s the most important part, because that’s the one that will give you the most insights. Let’s go over some things you can now do.
The information model
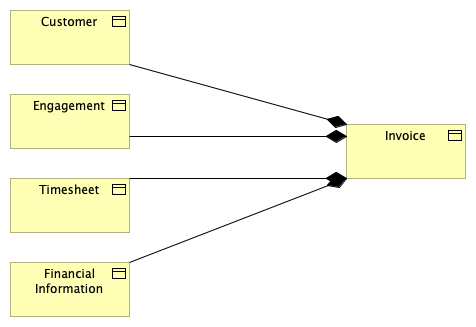
Here we are getting into DDD territory. We’ve made a story with just a few lines. If you want to create an invoice, you will need customer information, engagement information, timesheet information, and financial information.
Don’t forget that we are currently looking at a block diagram of this information. Behind these blocks might be a full documentation of what the information means, the sensitivity, and the guard points.
Using this information model, you can quickly discuss what is needed in different parts of the organization without diving in the deep end.
Want to know what applications handle client information? Follow the lines from information to data to applications.
Data classification
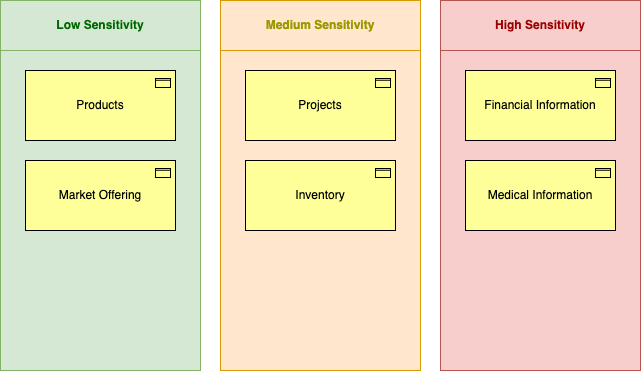
As mentioned in the previous part, these components may contain a lot of information. In this case, we displayed the information model per sensitivity. 4
Very quick to communicate and very easy to trace down. Again, like in the previous part, you can follow the lines down to get to the deeper parts.
You can also connect this information to business processes. Here you can tag certain business processes that handle data that might be sensitive. Are the people that do these processes trained in this sensitivity? Same with the people that develop the applications; can they have full access to the database?
Sources of truth
Combining this data into an information group enables you to have a central master. A single source of truth. This is a central place that holds the most up-to-date, full, and managed version of that information.
This can be a central hub for that domain. Want to have the employee information? Go to x.
The others
I can think of a few more but can’t keep up making schemas for these. Top of mind would be:
- Data lineage. Actually following the data through an organization. If two files are combined to follow a new data file, what should be the classification of this data file?
- Data governance. Maybe you want to have a standard of what an employee file should look like; you can only do that if you know what data is in an employee file.
At what detail should we go?
One of the biggest challenges in architecture is always the balance between having enough information and keeping it up to date. No information is, in my opinion, better than faulty information. And this is when it comes to information models exactly the same.
In the previous post, I’ve also talked about the C4 model, a model that gives different zoom levels on architecture. It is entirely possible to map out the information/data model to the code level, as in UML schemas. I, however, think that is not doable at an organization that would typically hire an enterprise architect; think 500-1000 applications. When you are talking at this level, the people that would be interested in the insights we could map would be developers, and they would also have to keep it up to date themselves. Adding an architect to that mix would just cause overhead.
The component level could be interesting from a solutions architecture point of view. But I think only for projects of the scale that a solution architect would be involved. Think about setting up new flows between multiple applications with some risk. Here we could map the interfaces per API endpoint, but again, keeping this up to date will be tricky and probably better done in something like Swagger.
So for me, the container level is ideal. Just enough information that it’s still mappable and not out of date a week later, but still of enough value to make strategic decisions on the landscape.
How to keep this going
So you know why we want to do it, what form it would take, and at what level; now it’s just how we can get started. And here comes the bad news. I haven’t found a single automated system that I thought was actually reliable enough to base architecture off. Either it’s just too much information to automate, or there are too many different connections, or there are too many manual data transfers (download a file and upload it somewhere else 5).
The reality is that the best way to capture this information is to interview application owners, one by one. And yes, that is a massive amount of work.
As I stated earlier, I’m scaling this post to organizations with 500-1000 applications. So that would be 500-100 half-hour calls. You could send forms to people to update the data once you want a refresh of the data, but the initial mapping is best done with interviews. This is, however, not a total waste of time; the amount of extra information you can get from talking to those application owners will pay back dividends on the investment. People know who you are, you might learn more about the applications, and your assumptions about the landscape might be totally turned on its head.
So yeah, that’s where my head is at when it comes to information models. They’re powerful tools, but only if they’re practical enough to stay useful. Too much detail, and they become impossible to maintain. Too little, and they don’t provide any real value. The trick is finding that balance: just enough structure to make sense of the chaos without adding more complexity than necessary.
Hope this was useful or at least gave you something to think about. If nothing else, it’s a good reminder that mapping information in an organization is as much about story telling as it is about diagrams.
In Archimate we talk about data objects and business objects. I personally don’t like those terms; they don’t give insight into what they mean. Normally I’m always a big fan of using the right term for the right component, but this is one of those rare exceptions. ↩︎
Technically you can with a junction, but it gets messy very quickly, so I would not advise it. ↩︎
If you’re not too familiar with these types of connections, no worries; everything is described in the Archimate spec. Diving too deep into these would make this post way too long ↩︎
Normally I like to make this a connection and not a parameter of the component, but for the sake of the post this is just a parameter. ↩︎
We can argue if we want to include that in our architecture in another post. ↩︎
further readings... in [Enterprise Architecture]

Governance: Documentation to support projects
Two weeks ago I wrote an article about governance and documentation on an organisational scale. This is the follow-up post that focuses on …
Read Entry
Governance: Documentation as a Knowledge Network
If you’ve known me for long enough, there will be a point where I’m going to pitch you the concept of
Read Entry
Systems Thinking in Enterprise Architecture
I first learned of systems thinking in the domain of city planning, and that is apparently also where the idea comes from. It was described …
Read Entry